Using deprecated ASM parameter might prevent your Cluster to start
Posted by Kamran Agayev A. on October 20th, 2017
Few days ago, I was testing some ASM parameters in my 3 nodes 12.2 Clusterware environment and used ASM_PREFERRED_READ_FAILURE_GROUPS parameter to see how I can force ASM to read specific failure group. Testings were successfull but I didn’t know that this parameter is deprecated in 12.2, and beside that, I didn’t imagine that it might cause me a downtime and prevent Clusterware to start.
Here’s the scenario that you can try in your test environment. First of all, I set this parameter to the failure group and then resetted it back:
SQL> alter system set ASM_PREFERRED_READ_FAILURE_GROUPS=”;
System altered.
SQL>
Then I made some hardware changes to my nodes and rebooted them. After nodes are rebooted, I checked the status of the clusterware, and it was down at all nodes.
[oracle@oratest01 ~]$ crsctl check crs
CRS-4638: Oracle High Availability Services is online
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4529: Cluster Synchronization Services is online
CRS-4534: Cannot communicate with Event Manager
[oracle@oratest01 ~]$ crsctl check cluster -all
**************************************************************
oratest01:
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4529: Cluster Synchronization Services is online
CRS-4534: Cannot communicate with Event Manager
**************************************************************
oratest02:
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4530: Communications failure contacting Cluster Synchronization Services daemon
CRS-4534: Cannot communicate with Event Manager
**************************************************************
oratest03:
CRS-4535: Cannot communicate with Cluster Ready Services
CRS-4530: Communications failure contacting Cluster Synchronization Services daemon
CRS-4534: Cannot communicate with Event Manager
**************************************************************
Next, I check if ohasd and crsd background processes are up
[root@oratest01 oracle]# ps -ef|grep init.ohasd|grep -v grep
root 1252 1 0 02:49 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
[root@oratest01 oracle]#
[root@oratest01 oracle]# ps -ef|grep crsd|grep -v grep
[root@oratest01 oracle]#
OHAS was up and running, but CRSD not. ASM instance should be up in order to bring the crsd, so I checked if ASM instance is up, but it was also down:
[oracle@oratest01 ~]$ ps -ef | grep smon
oracle 5473 3299 0 02:50 pts/0 00:00:00 grep –color=auto smon
[oracle@oratest01 ~]$
Next, I decided to check log files. Logged in to adrci to find the centralized Clusterware log folder:
[oracle@oratest01 ~]$ adrci
ADRCI: Release 12.2.0.1.0 – Production on Fri Oct 20 02:51:59 2017
Copyright (c) 1982, 2017, Oracle and/or its affiliates. All rights reserved.
ADR base = “/u01/app/oracle”
adrci> show home
ADR Homes:
diag/rdbms/_mgmtdb/-MGMTDB
diag/rdbms/proddb/proddb1
diag/asm/user_root/host_4288267646_107
diag/asm/user_oracle/host_4288267646_107
diag/asm/+asm/+ASM1
diag/crs/oratest01/crs
diag/clients/user_root/host_4288267646_107
diag/clients/user_oracle/host_4288267646_107
diag/tnslsnr/oratest01/asmnet1lsnr_asm
diag/tnslsnr/oratest01/listener_scan1
diag/tnslsnr/oratest01/listener_scan2
diag/tnslsnr/oratest01/listener_scan3
diag/tnslsnr/oratest01/listener
diag/tnslsnr/oratest01/mgmtlsnr
diag/asmtool/user_root/host_4288267646_107
diag/asmtool/user_oracle/host_4288267646_107
diag/apx/+apx/+APX1
diag/afdboot/user_root/host_4288267646_107
adrci> exit
[oracle@oratest01 ~]$ cd /u01/app/oracle/diag/crs/oratest01/crs
[oracle@oratest01 crs]$cd trace
[oracle@oratest01 trace]$ tail -f evmd.trc
2017-10-20 02:54:26.533 : CRSOCR:2840602368: OCR context init failure. Error: PROC-32: Cluster Ready Services on the local node is not running Messaging error [gipcretConnectionRefused] [29]
2017-10-20 02:54:27.552 : CRSOCR:2840602368: OCR context init failure. Error: PROC-32: Cluster Ready Services on the local node is not running Messaging error [gipcretConnectionRefused] [29]
2017-10-20 02:54:28.574 : CRSOCR:2840602368: OCR context init failure. Error: PROC-32: Cluster Ready Services on the local node is not running Messaging error [gipcretConnectionRefused] [29]
From evmd.trc file it can bees that OCR was not initialized. Then I check alert.log file:
[oracle@oratest01 trace]$ tail -f alert.log
2017-10-20 02:49:49.613 [OCSSD(3825)]CRS-1605: CSSD voting file is online: AFD:DATA1; details in /u01/app/oracle/diag/crs/oratest01/crs/trace/ocssd.trc.
2017-10-20 02:49:49.627 [OCSSD(3825)]CRS-1672: The number of voting files currently available 1 has fallen to the minimum number of voting files required 1.
2017-10-20 02:49:58.812 [OCSSD(3825)]CRS-1601: CSSD Reconfiguration complete. Active nodes are oratest01 .
2017-10-20 02:50:01.154 [OCTSSD(5351)]CRS-8500: Oracle Clusterware OCTSSD process is starting with operating system process ID 5351
2017-10-20 02:50:01.161 [OCSSD(3825)]CRS-1720: Cluster Synchronization Services daemon (CSSD) is ready for operation.
2017-10-20 02:50:02.099 [OCTSSD(5351)]CRS-2403: The Cluster Time Synchronization Service on host oratest01 is in observer mode.
2017-10-20 02:50:03.233 [OCTSSD(5351)]CRS-2407: The new Cluster Time Synchronization Service reference node is host oratest01.
2017-10-20 02:50:03.235 [OCTSSD(5351)]CRS-2401: The Cluster Time Synchronization Service started on host oratest01.
2017-10-20 02:50:10.454 [ORAAGENT(3362)]CRS-5011: Check of resource “ora.asm” failed: details at “(:CLSN00006:)” in “/u01/app/oracle/diag/crs/oratest01/crs/trace/ohasd_oraagent_oracle.trc”
2017-10-20 02:50:18.692 [ORAROOTAGENT(3198)]CRS-5019: All OCR locations are on ASM disk groups [DATA], and none of these disk groups are mounted. Details are at “(:CLSN00140:)” in “/u01/app/oracle/diag/crs/oratest01/crs/trace/ohasd_orarootagent_root.trc”.
CRS didn’t started as the ASM is not up and running. To checking why ASM wasn’t started upon the server book sounded good starting point for the investigation, so logged in and tried to start ASM instance:
[oracle@oratest01 ~]$ sqlplus / as sysasm
SQL*Plus: Release 12.2.0.1.0 Production on Fri Oct 20 02:55:12 2017
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup
ORA-01078: failure in processing system parameters
SQL> startup
ORA-01078: failure in processing system parameters
SQL> startup
ORA-01078: failure in processing system parameters
SQL>
I checked ASM alert.log file, but it didn’t provide enough information why ASM didn’t start:
NOTE: ASM client -MGMTDB:_mgmtdb:clouddb disconnected unexpectedly.
NOTE: check client alert log.
NOTE: Trace records dumped in trace file /u01/app/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_ufg_20658_-MGMTDB__mgmtdb.trc
NOTE: cleaned up ASM client -MGMTDB:_mgmtdb:clouddb connection state (reg:2993645709)
2017-10-20T02:47:20.588256-04:00
NOTE: client +APX1:+APX:clouddb deregistered
2017-10-20T02:47:21.201319-04:00
NOTE: detected orphaned client id 0x10004.
2017-10-20T02:48:49.613505-04:00
WARNING: Write Failed, will retry. group:2 disk:0 AU:9067 offset:151552 size:4096
path:AFD:DATA1
incarnation:0xf0a9ba5e synchronous result:’I/O error’
subsys:/opt/oracle/extapi/64/asm/orcl/1/libafd12.so krq:0x7f8fced52240 bufp:0x7f8fc9262000 osderr1:0xfffffff8 osderr2:0xc28
IO elapsed time: 0 usec Time waited on I/O: 0 usec
ERROR: unrecoverable error ORA-15311 raised in ASM I/O path; terminating process 20200
The problem seemed to be in the parameter file of ASM, so I decided to start it with default parameters and then investigate. For this, I opened searched for the string “parameters” in the ASM alert.log file to get list of parameters and paramter file location:
[oracle@oratest01 trace]$ more +ASM1_alert.log
Using parameter settings in server-side spfile +DATA/clouddb/ASMPARAMETERFILE/registry.253.949654249
System parameters with non-default values:
large_pool_size = 12M
remote_login_passwordfile= “EXCLUSIVE”
asm_diskstring = “/dev/sd*”
asm_diskstring = “AFD:*”
asm_diskgroups = “NEW”
asm_diskgroups = “TESTDG”
asm_power_limit = 1
_asm_max_connected_clients= 4
NOTE: remote asm mode is remote (mode 0x202; from cluster type)
2017-08-11T10:22:24.834431-04:00
Cluster Communication is configured to use IPs from: GPnP
Then I created parameter file (/tmp/pfile_asm.ora) and started the instance:
SQL> startup pfile=’/home/oracle/pfile_asm.ora’;
ASM instance started
Total System Global Area 1140850688 bytes
Fixed Size 8629704 bytes
Variable Size 1107055160 bytes
ASM Cache 25165824 bytes
ASM diskgroups mounted
SQL> exit
Great! ASM is up. Now I can restore my parameter file and try to start ASM with it:
[oracle@oratest01 ~]$ sqlplus / as sysasm
SQL> create pfile=’/home/oracle/pfile_orig.ora’ from spfile=’+DATA/clouddb/ASMPARAMETERFILE/registry.253.957837377′;
File created.
SQL>
And here is entry of my original ASM parameter file:
[oracle@oratest01 ~]$ more /home/oracle/pfile_orig.ora
+ASM1.__oracle_base=’/u01/app/oracle’#ORACLE_BASE set from in memory value
+ASM2.__oracle_base=’/u01/app/oracle’#ORACLE_BASE set from in memory value
+ASM3.__oracle_base=’/u01/app/oracle’#ORACLE_BASE set from in memory value
+ASM3._asm_max_connected_clients=5
+ASM2._asm_max_connected_clients=8
+ASM1._asm_max_connected_clients=5
*.asm_diskgroups=’DATA’,’ACFSDG’#Manual Mount
*.asm_diskstring=’/dev/sd*’,’AFD:*’
*.asm_power_limit=1
*.asm_preferred_read_failure_groups=”
*.large_pool_size=12M
*.remote_login_passwordfile=’EXCLUSIVE’
Good. Now let’s start ASM with it:
SQL> shut abort
ASM instance shutdown
SQL> startup pfile=’/home/oracle/pfile_orig.ora’;
ORA-32006: ASM_PREFERRED_READ_FAILURE_GROUPS initialization parameter has been deprecated
ORA-01078: failure in processing system parameters
SQL>
Wohoo. ASM failed to start because of deprecated parameter?! Let’s remove it and start ASM without ASM_PREFERRED_READ_FAILURE_GROUPS parameter:
[oracle@oratest01 ~]$ sqlplus / as sysasm
Connected to an idle instance.
SQL> startup pfile=’/home/oracle/pfile_orig.ora’;
ASM instance started
Total System Global Area 1140850688 bytes
Fixed Size 8629704 bytes
Variable Size 1107055160 bytes
ASM Cache 25165824 bytes
ASM diskgroups mounted
SQL>
It is started! Next I create ASM parameter file based on this pfile and start the instance:
SQL> create spfile=’+DATA’ from pfile=’/home/oracle/pfile_orig.ora’;
File created.
SQL> shut immediate
ASM diskgroups dismounted
ASM instance shutdown
SQL> startup
ASM instance started
Total System Global Area 1140850688 bytes
Fixed Size 8629704 bytes
Variable Size 1107055160 bytes
ASM Cache 25165824 bytes
ASM diskgroups mounted
SQL>
After having ASM up and running I restart the clusterware on all nodes and check the status:
[root@oratest01 ~]$ crsctl stop cluster –all
[root@oratest01 ~]$ crsctl start cluster –all
[oracle@oratest01 ~]$ crsctl check cluster -all
**************************************************************
oratest01:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
**************************************************************
CRS-4404: The following nodes did not reply within the allotted time:
oratest02, oratest03
The first node is up, but I wasn’t able to get status of clusterware in other nodes and got CRS-4404 error. To solve it, kill gpnpd process on all nodes and run the command again:
[oracle@oratest01 ~]$ ps -ef | grep gpn
oracle 3418 1 0 02:49 ? 00:00:15 /u01/app/12.2.0.1/grid/bin/gpnpd.bin
[oracle@oratest01 ~]$ kill -9 3418
[oracle@oratest01 ~]$ ps -ef | grep gpn
oracle 16169 1 3 06:52 ? 00:00:00 /u01/app/12.2.0.1/grid/bin/gpnpd.bin
[oracle@oratest01 ~]$ crsctl check cluster -all
**************************************************************
oratest01:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
**************************************************************
oratest02:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
**************************************************************
oratest03:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
**************************************************************
[oracle@oratest01 ~]$
From this blog post you can learn step by step clusterware startup troubleshooting and not to use depracated ASM parameter
Posted in RAC issues | No Comments »
 So if you are a reader of my book, please send me your photo with my book and become a famous!
So if you are a reader of my book, please send me your photo with my book and become a famous! 
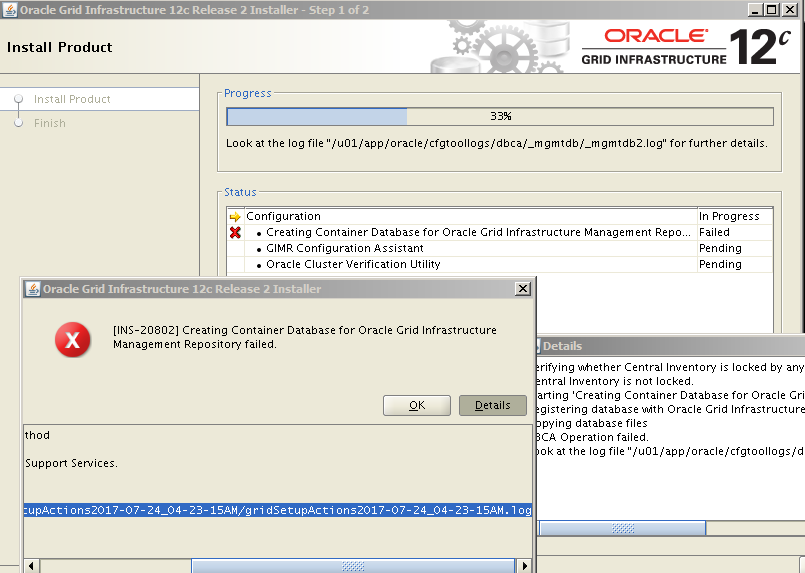


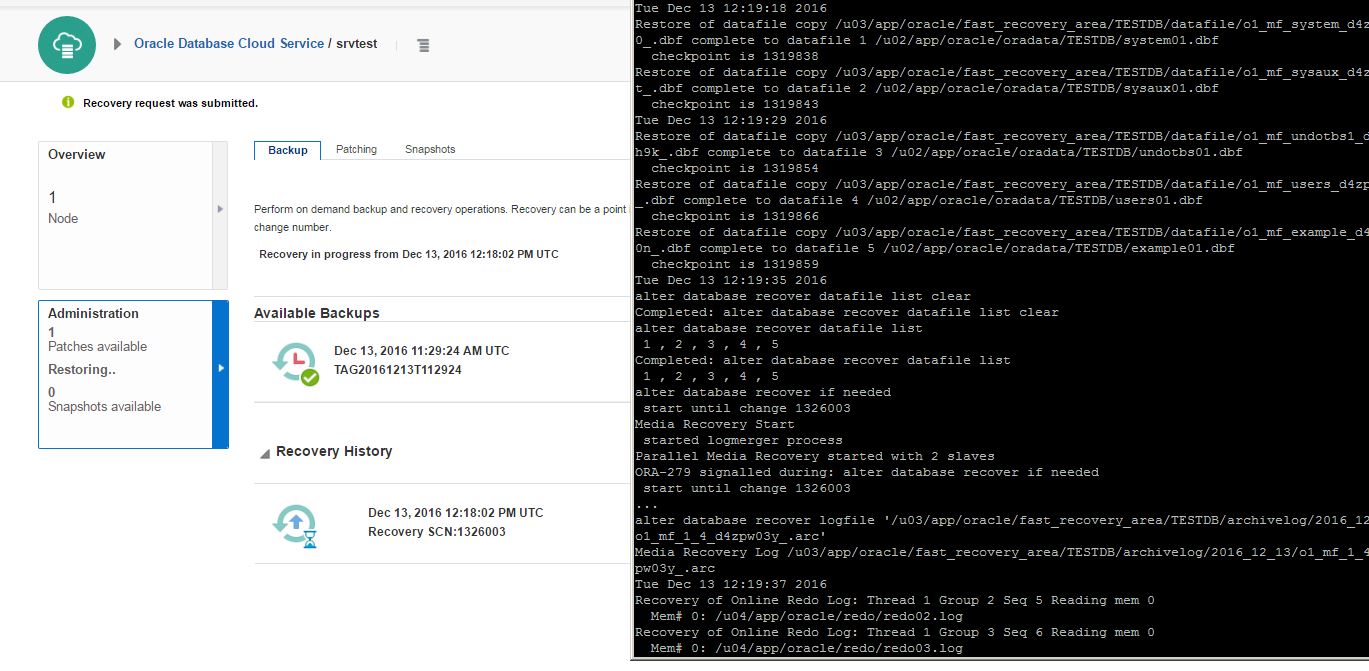
 in the database host:
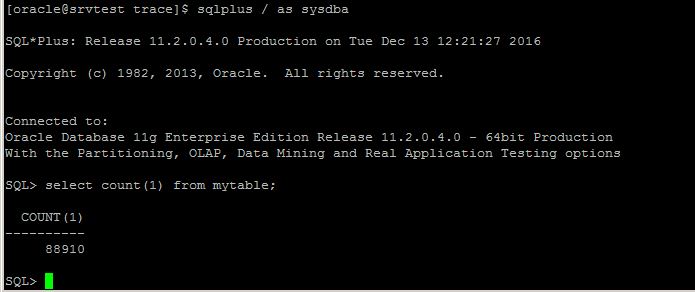
in the database host: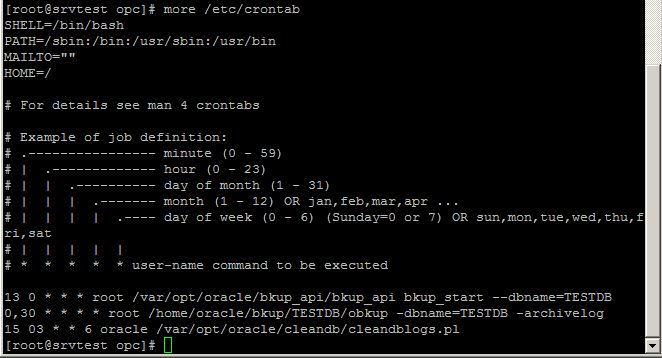
 dministration section
dministration section
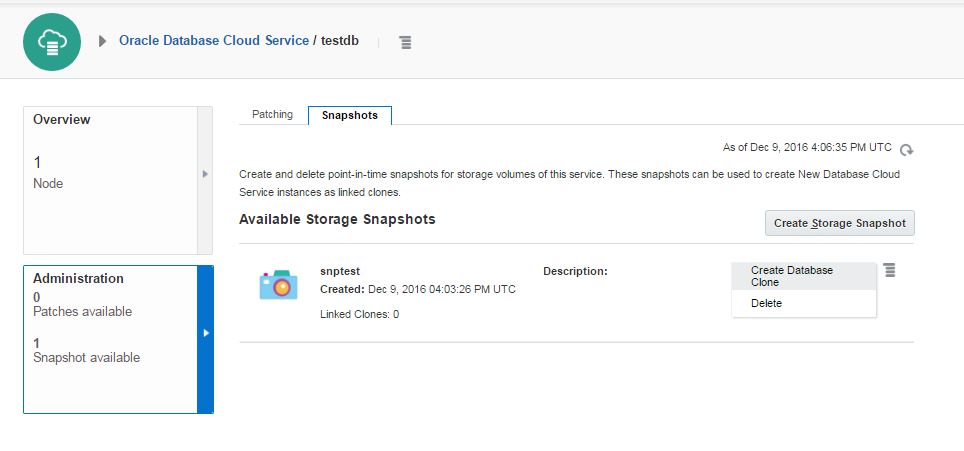
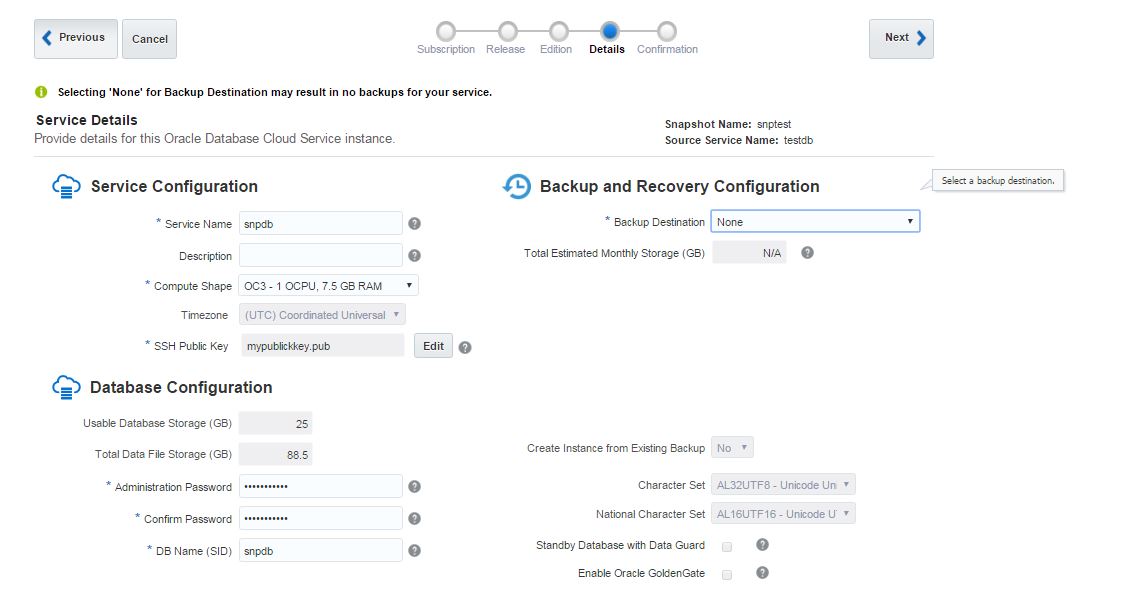
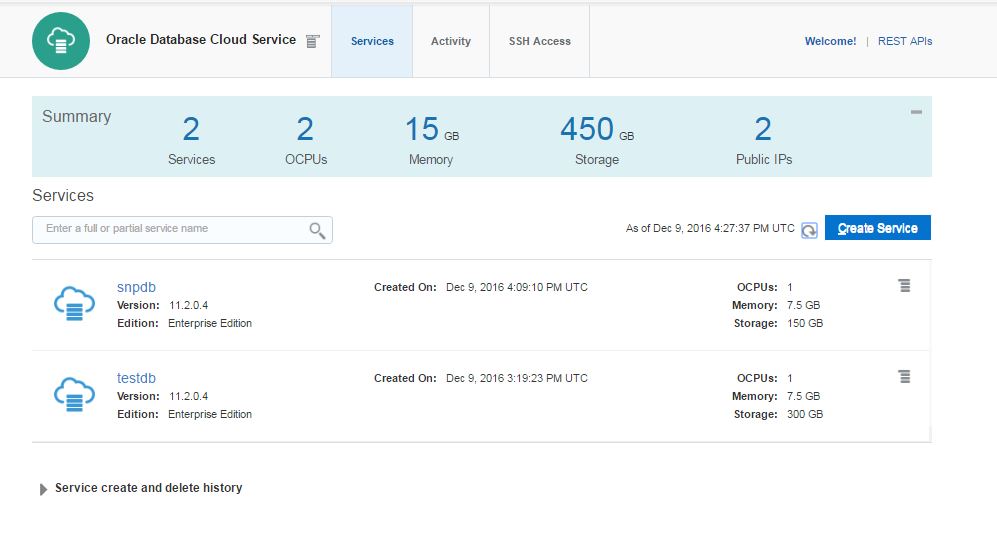 l be created
l be created