







Solution for ORA-27154: post/wait create failed ; ORA-27302: failure occurred at: sskgpbitsper
Posted by Kamran Agayev A. on 21st June 2019
Today, while creating an empty database in Exadata machine where there was enough free space and memory, we got the following error:
SYS@TEST> startup nomount ORA-27154: post/wait create failed ORA-27300: OS system dependent operation:semget failed with status: 28 ORA-27301: OS failure message: No space left on device ORA-27302: failure occurred at: sskgpbitsper
The problem wasn’t related with the space at all, even from the error message we see “No space left on device”.
From the error output, I realized “OS system dependent operation:semget“, where “sem” means “semaphore“. Having enough free memory and space, the process couldn’t allocate necessary semaphore, either because of the kernel parameter wasn’t configured correctly, or all memory is occupied. To get information about semaphores and shared memory, I ran ipcs command:
[oracle@node2~]$ ipcs
------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x00000000 0 root 644 64 2 dest 0x00000000 32769 root 644 16384 2 dest 0x00000000 65538 root 644 280 2 dest 0x00000000 98307 root 644 80 2 0x00000000 131076 root 644 16384 2 0x00000000 163845 root 644 280 2 0x00000000 262602758 oracle 640 4096 0
------ Semaphore Arrays -------- key semid owner perms nsems 0x61000625 98306 root 666 1 0x00000000 163844 root 666 3 0x00000000 1769477 root 666 3 0x00000000 4096006 root 666 3 0xd9942a14 3604487 oracle 600 514 0xd9942a15 3637256 oracle 600 514 0xd9942a16 3670025 oracle 600 514 0x192b36e8 219578379 oracle 640 1004 0x5f94bc50 6062092 oracle 640 1004 0x00000000 286752781 root 666 3 0xaa3762f4 6324238 oracle 640 154
The list was long, so I decided to count the rows
[oracle@node2 ~]$ ipcs -s | wc -l 256
So overall I have 256 semaphores allocated. Then I checked /etc/sysctl.conf file for the KERNEL.SEM parameter:
[oracle@node2 ~]$ more /etc/sysctl.conf | grep sem kernel.sem = 1024 60000 1024 256 [oracle@node2 ~]$
You can get more detailed output from ipcs -ls command as follows:
[oracle@node2 ~]$ ipcs -ls
------ Semaphore Limits -------- max number of arrays = 256 max semaphores per array = 1024 max semaphores system wide = 60000 max ops per semop call = 1024 semaphore max value = 32767
The last column indicates the maximum number of semaphore sets for the entire OS. In this case you have to options to solve the problem:
- Increase the max number of arrays parameter in the /etc/sysctl.conf file
- Remove unnecessary semaphores
Increasing max number of arrays parameter is the easiest (and the fastest) way. Here how it works:
1. Get the value for the SEM parameter:
[root@node2 ~]# cat /etc/sysctl.conf | grep sem kernel.sem = 1024 60000 1024 256 [root@node2 ~]#
2. Edit it and change it to 260 (more than the value you get from ” ipcs -s | wc -l” command) and run the following command to set the parameter to be persistent
/sbin/sysctl -p
3. Create a dummy parameter file and start the instance in NOMOUNT mode to see if the oracle user can get a semaphore from the memory:
[oracle@node2 dbs] mode initTEST.ora
db_name=TEST
sga_size=2g
[oracle@node2 ~] export ORACLE_SID=TEST
[oracle@node2 ~] sqlplus / as sysdba
SYS@TEST> startup nomount ORACLE instance started.
Total System Global Area 2137886720 bytes Fixed Size 2254952 bytes Variable Size 956303256 bytes Database Buffers 1090519040 bytes Redo Buffers 88809472 bytes SYS@TEST>
It worked!
The second option to solve the problem, is to find out the ‘aged’ semaphores from the memory and remove them. Each semaphore is linked to the PID in the OS. In the following example I have overall 256 semaphores where 23 of them are related with oracle user (db instances etc.) and 229 of them related with root user. Most processes that hold the semaphore in the memory died long time ago, but semaphores didn’t age out. To find and kill the PID of the semaphore, we run ipcs command with -i parameter. First let’s get list of semaphores under oracle user and check one of them as follows:
[root@node2 ~]# ipcs -s | grep oracle 0xcfe88130 3473414 oracle 600 514 0xcfe88131 3506183 oracle 600 514 0xcfe88132 3538952 oracle 600 514 0xf0720010 411041803 oracle 640 802 0xf8121f34 145653772 oracle 640 1004 0xf0720011 411074573 oracle 640 802 0xf0720012 411107342 oracle 640 802 0xc5d91710 196444189 oracle 640 504 0x86d48ae8 44236836 oracle 640 304 0x67556608 199786542 oracle 640 876 0x67556609 199819311 oracle 640 876 0x6755660a 199852080 oracle 640 876 0x6755660b 199884849 oracle 640 876 0x6755660c 199917618 oracle 640 876 0x806b87cc 157450352 oracle 640 752 0x806b87cd 157483121 oracle 640 752 0x806b87ce 157515892 oracle 640 752 [root@node2 ~]#
Next, we run ipcs command with -i parameter to get the list of PIDs as follows:
[root@node2 ~]# ipcs -s -i 157450352 | more Semaphore Array semid=157450352 uid=1001 gid=1002 cuid=1001 cgid=1002 mode=0640, access_perms=0640 nsems = 752 otime = Fri Jun 21 18:51:23 2019 ctime = Fri Jun 21 18:51:23 2019 semnum value ncount zcount pid 0 1 0 0 315611 1 4893 0 0 315611 2 10236 0 0 315611 3 32760 0 0 315611 4 0 0 0 0 5 0 0 0 0 6 0 0 0 315729 7 0 1 0 315731 8 0 0 0 0 9 0 1 0 315739 10 0 0 0 0 11 0 1 0 315743 12 0 0 0 315745 13 0 1 0 315747 14 0 1 0 315749
Next, we run ps command and check the PID:
[root@node2 ~]# ps -fp 315729 UID PID PPID C STIME TTY TIME CMD oracle 315729 1 0 2018 ? 01:14:13 ora_pmon_SNEWDB [root@node2 ~]#
As you see, we found out that the specific semaphore is associated with the database instance. Now let’s repeat the same steps for the semaphores of the root user:
[oracle@node2 ~]$ ipcs -s |grep root 0x61000625 98306 root 666 1 0x00000000 163844 root 666 3 0x00000000 1769477 root 666 3 0x00000000 4096006 root 666 3 0x00000000 248774666 root 666 3 0x00000000 286752781 root 666 3 0x00000000 6357007 root 666 3
Now we run ipcs -s -i command for the semaphore which is marked in bold to find the PID :
[oracle@node2 ~]$ ipcs -s -i 248774666
Semaphore Array semid=248774666 uid=0 gid=11140 cuid=0 cgid=11140 mode=0666, access_perms=0666 nsems = 3 otime = Sun Dec 16 18:34:22 2018 ctime = Sun Dec 16 18:34:22 2018 semnum value ncount zcount pid 0 1024 0 0 156155 1 32000 0 0 156155 2 0 0 0 156155
If we check the PID in the system, we see that it’s not available:
[oracle@node2 ~]$ ps -fp 156155 UID PID PPID C STIME TTY TIME CMD [oracle@node2 ~]$
Now we can safely remove that semaphore from the memory using ipcrm command in order to release space for new semaphores:
[root@node2 ~]# ipcrm -s 248774666 [root@node2 ~]#
Let's check if it was removed:
[root@node2 ~]# ipcrm -s 248774666 ipcrm: invalid id (248774666)
[root@node2 ~]#
As you see, we found out the semaphores which associated process is not available in the system, and removed it to make space for new semaphores. Now let’s start the instance:
SYS@TEST> startup nomount ORACLE instance started.
Total System Global Area 2137886720 bytes Fixed Size 2254952 bytes Variable Size 956303256 bytes Database Buffers 1090519040 bytes Redo Buffers 88809472 bytes SYS@TEST>
Posted in Administration | No Comments »
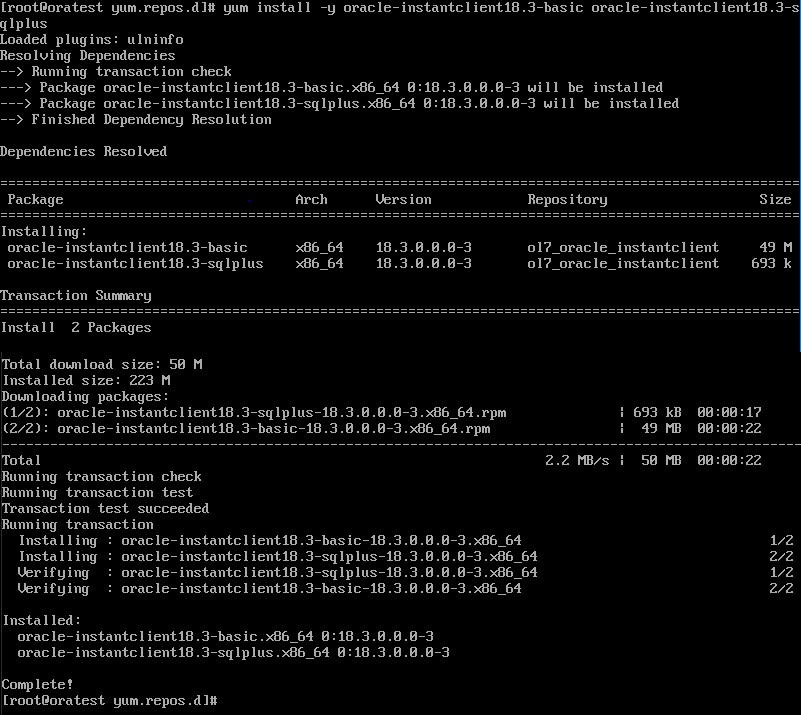

 I will keep updating the pdf and hope it will be much easier fo you to get all articles in one shot!
I will keep updating the pdf and hope it will be much easier fo you to get all articles in one shot!