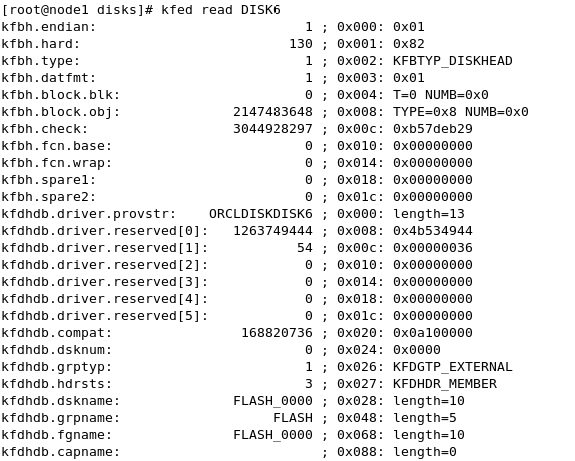
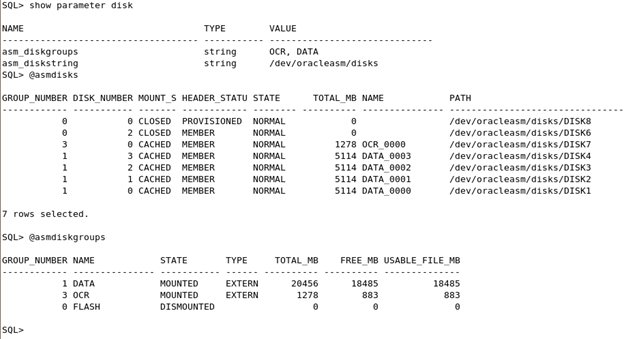
Struggling with RAC Installation – ORA-15018: diskgroup cannot be created
Posted by Kamran Agayev A. on 9th December 2014
I said it before. It was only once that I succeeded to install Oracle Clusterware without any issues and that was during OCM exam  I didn’t hit any bug, I didn’t re-configured anything. The installation went smooth. But …
I didn’t hit any bug, I didn’t re-configured anything. The installation went smooth. But …
Today, I got all following errors :
ORA-15032: not all alterations performed
ORA-15131: block of file in diskgroup could not be read
ORA-15018: diskgroup cannot be created
ORA-15031: disk specification ‘/dev/mapper/mpathh’ matches no disks
ORA-15025: could not open disk “/dev/mapper/mpathh”
ORA-15056: additional error message
ORA-15017: diskgroup “OCR_MIRROR” cannot be mounted
ORA-15063: ASM discovered an insufficient number of disks for diskgroup “OCR_MIRROR”
ORA-15033: disk ‘/dev/mapper/mpathh’ belongs to diskgroup “OCR_MIRROR”
In the beginning, while installing Oracle 11gRAC, I got the following error:
CRS-2672: Attempting to start ‘ora.diskmon’ on ‘vsme_ora1’
CRS-2676: Start of ‘ora.diskmon’ on ‘vsme_ora1’ succeeded
CRS-2676: Start of ‘ora.cssd’ on ‘vsme_ora1’ succeeded
Disk Group OCR_MIRROR creation failed with the following message:
ORA-15018: diskgroup cannot be created
ORA-15031: disk specification ‘/dev/mapper/mpathh’ matches no disks
ORA-15025: could not open disk “/dev/mapper/mpathh”
ORA-15056: additional error message
Configuration of ASM … failed
see asmca logs at /home/oracle/app/cfgtoollogs/asmca for details
Did not succssfully configure and start ASM at /home/oracle/11.2.4/grid1/crs/install/crsconfig_lib.pm line 6912.
/home/oracle/11.2.4/grid1/perl/bin/perl -I/home/oracle/11.2.4/grid1/perl/lib -I/home/oracle/11.2.4/grid1/crs/install /home/oracle/11.2.4/grid1/crs/install/rootcrs.pl execution failed
Bad news is that the installation failed. Good news is that I can easily restart the installation again without any issues, as the root.sh script is rest restartable. If you don’t need to install the software on all nodes again, solve the problem and run root.sh script again. If the problem is solved, it will sun smoothly. If you need to install the software on all nodes, you have to deconfigure and run the installation again. To remove the failed RAC installation, run rootcrs.pl script on all nodes except the last one, as follows:
$GRID_HOME/crs/install/rootcrs.pl -verbose -deconfig –force
Run the following command on the last node:
$GRID_HOME/crs/install/rootcrs.pl -verbose -deconfig –force –lastnode
Now, run ./runInstaller command and start the installation again.
So let’s go back to the problem. It was claiming that “disk specification ‘/dev/mapper/mpathh’ matches no disks”. Hmm … The first thing that came in my mind was permission of the disk. So I checked it, it was root:disk. I changed it to oracle:dba and run root.sh script. Got the same problem again.
I checked the following log file:
/home/oracle/app/cfgtoollogs/asmca
[main] [ 2014-12-09 17:26:29.220 AZT ] [UsmcaLogger.logInfo:143] CREATE DISKGROUP SQL: CREATE DISKGROUP OCR_MIRROR EXTERNAL REDUNDANCY DISK ‘/dev/mapper/mpathh’ ATTRIBUTE ‘compatible.asm’=’11.2.0.0.0′,’au_size’=’1M’
[main] [ 2014-12-09 17:26:29.295 AZT ] [SQLEngine.done:2189] Done called
[main] [ 2014-12-09 17:26:29.296 AZT ] [UsmcaLogger.logException:173] SEVERE:method oracle.sysman.assistants.usmca.backend.USMDiskG
roupManager:createDiskGroups
[main] [ 2014-12-09 17:26:29.296 AZT ] [UsmcaLogger.logException:174] ORA-15018: diskgroup cannot be created
ORA-15031: disk specification ‘/dev/mapper/mpathh’ matches no disks
ORA-15025: could not open disk “/dev/mapper/mpathh”
ORA-15056: additional error message
Oracle wasn’t able to create the diskgroup claiming that the specified device matches no disks. I logged in to the ASM instance and tried to create the diskgroup by my own:
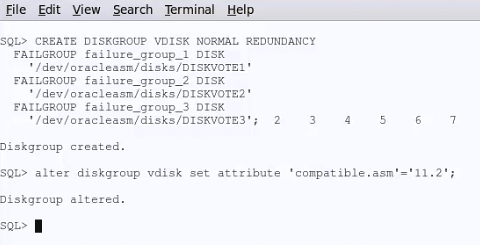
SQL> CREATE DISKGROUP OCR_MIRROR EXTERNAL REDUNDANCY DISK ‘/dev/mapper/mpathh’ ATTRIBUTE ‘compatible.asm’=’11.2.0.0.0′,’au_size’=’1M’;
SQL> CREATE DISKGROUP OCR_MIRROR EXTERNAL REDUNDANCY DISK ‘/dev/mapper/mpathh’ ATTRIBUTE ‘compatible.asm’=’11.2.0.0.0′,’au_size’=’1M’
ERROR at line 1:
ORA-15018: diskgroup cannot be created
ORA-15031: disk specification ‘/dev/mapper/mpathh’ matches no disks
ORA-15025: could not open disk “/dev/mapper/mpathh”
ORA-15056: additional error message
Linux-x86_64 Error: 13: Permission denied
Additional information: 42
Additional information: -807671168
I checked the permission, it was root:disk . I changed it to oracle:dba and run the command again.
SQL> CREATE DISKGROUP OCR_MIRROR EXTERNAL REDUNDANCY DISK ‘/dev/mapper/mpathh’ ATTRIBUTE ‘compatible.asm’=’11.2.0.0.0′,’au_size’=’1M’
ERROR at line 1:
ORA-15018: diskgroup cannot be created
ORA-15017: diskgroup “OCR_MIRROR” cannot be mounted
ORA-15063: ASM discovered an insufficient number of disks for diskgroup “OCR_MIRROR”
I run the query again, this time got different message:
SQL> CREATE DISKGROUP OCR_MIRROR EXTERNAL REDUNDANCY DISK ‘/dev/mapper/mpathh’ ATTRIBUTE ‘compatible.asm’=’11.2.0.0.0′,’au_size’=’1M’
ERROR at line 1:
ORA-15018: diskgroup cannot be created
ORA-15033: disk ‘/dev/mapper/mpathh’ belongs to diskgroup “OCR_MIRROR”
I tried to mount the diskgroup and got the following error:
SQL> alter diskgroup ocr_mirror mount;
alter diskgroup ocr_mirror mount
*
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15017: diskgroup “OCR_MIRROR” cannot be mounted
ORA-15063: ASM discovered an insufficient number of disks for diskgroup “OCR_MIRROR”
I checked the permission. It was changed again! I changed it back to oracle:dba and tried to mount the diskgroup and got the following error!
SQL> alter diskgroup ocr_mirror mount
ERROR at line 1:
ORA-15032: not all alterations performed
ORA-15131: block of file in diskgroup could not be read
Ohhh … Come on! I logged to the ASM instance, and queried the v$asm_disk and v$asm_diskgroup views.
SQL> select count(1) from v$asm_disk;
COUNT(1)
———-
0
I changed permission to oracle:dba and run the query again:
SQL> /
COUNT(1)
———-
1
I run again:
SQL> select count(1) from v$asm_diskgroup;
COUNT(1)
———-
0
What??? The permission is changed automatically while I query V$ASM_DISKGROUP view? Yes … Even, when you query V$ASM_DISKGROUP, Oracle checks ASM_DISKSTRING parameter and query the header of all disks that are listed in that parameter. For more information on this topic, you can check my following blog post:
V$ASM_DISKGROUP displays information from the header of ASM disks
So, this means that when I query V$ASM_DISK view, Oracle scan the disk (with the process that runs under root user) and change the permission of the disk.
After making change to the /etc/udev/rules.d/99-oracle-asmdevices.rules file and adding the following line, the problem solved:
NAME=”/dev/mapper/mpathh”, OWNER=”oracle”, GROUP=”dba”, MODE=”0660″
So I checked the permission of the disks again after querying V$ASM_DISK multiple time, and made sure that it doesn’t change the permission of the disk and run root.sh script. Everything worked fine and I got the following output:
ASM created and started successfully.
Disk Group OCR_MIRROR mounted successfully.
clscfg: -install mode specified
Successfully accumulated necessary OCR keys.
Creating OCR keys for user ‘root’, privgrp ‘root’..
Operation successful.
CRS-4256: Updating the profile
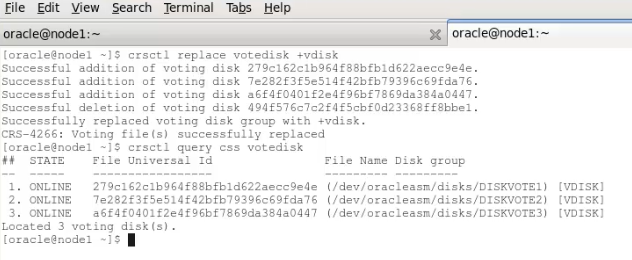
Successful addition of voting disk 5feed4cb66df4f43bf334c3a8d73af92.
Successfully replaced voting disk group with +OCR_MIRROR.
CRS-4256: Updating the profile
CRS-4266: Voting file(s) successfully replaced
## STATE File Universal Id File Name Disk group
— —– —————– ——— ———
1. ONLINE 5feed4cb66df4f43bf334c3a8d73af92 (/dev/mapper/mpathh) [OCR_MIRROR]
Located 1 voting disk(s).
CRS-2672: Attempting to start ‘ora.asm’ on ‘vsme_ora1’
CRS-2676: Start of ‘ora.asm’ on ‘vsme_ora1’ succeeded
CRS-2672: Attempting to start ‘ora.OCR_MIRROR.dg’ on ‘vsme_ora1’
CRS-2676: Start of ‘ora.OCR_MIRROR.dg’ on ‘vsme_ora1’ succeeded
Preparing packages for installation…
cvuqdisk-1.0.9-1
Configure Oracle Grid Infrastructure for a Cluster … succeeded
Posted in RAC issues | 1 Comment »